GKE Compute Cost Comparisons In Small Clusters
Comparing GKE's Manual pools, Node-AutoProvisioning & Autopilot to see which achieves the lowest cost for the least inconvenience

I’ve been running a short-term experiment across the GKE Compute options within my “Home Lab” (read: GCP-hosted Google Kubernetes Engine) with a view to optimise for a balance between ease of operation and cost efficiency. If that sounds useful to you, then by all means read on!
Let’s dive right in with the Billing data. The chart below shows the view of costs over the course of my two-month experiment for this small GKE Cluster. I’ll be stepping across this graph to detail each experiment I ran and what led to these outcomes, as well as some of the trade-offs along the way.
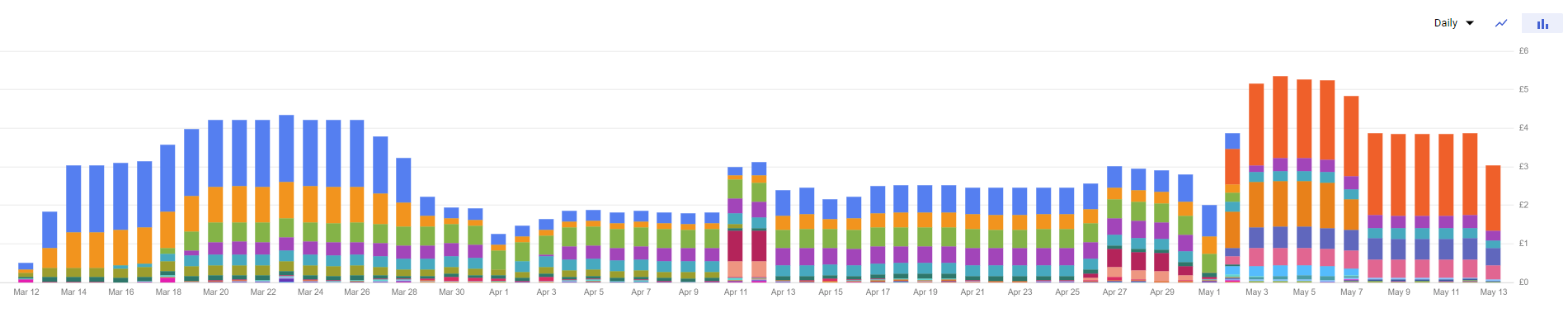
GCP Spend - Two Months
Note that the collection of workloads deployed did not fluctuate much over the course of the experiment - we’re talking about 13 or so Deployments with maybe the odd replica dropped here and there, but nothing significant.
The As-Is
Let’s start by describing the steady state. Prior to the experiments this cluster ticked along happily on 3 x e2-medium Spot Instance machines in a Zonal cluster. The initial part of the graph shows this from a cost perspective:
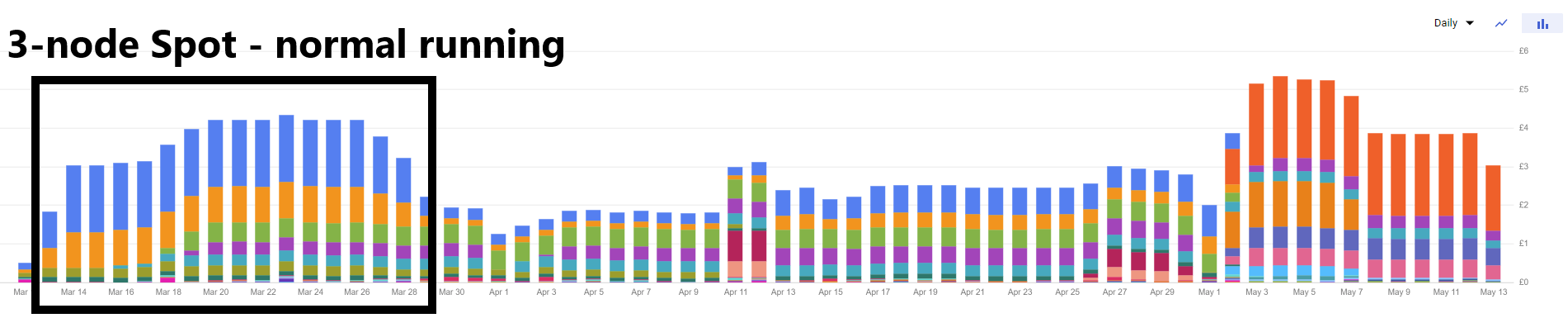
GCP Spend - 3 x Spot Nodes, Normal Running
The remaining costs are standing charges for things like Secret Manager, Network Load Balancing and PD Storage - these do not fluctuate very much throughout the course of the experiment - pennies here and there, as the load on these apps is consistent.
Squeeeeeeeeeze Me Seymour
My first act was to try to squeeze this down to two nodes - which I managed, ish. I was aggressive with setting of resource requests & limits for my Pods whilst still ensuring everything was running, yielding the following saving:
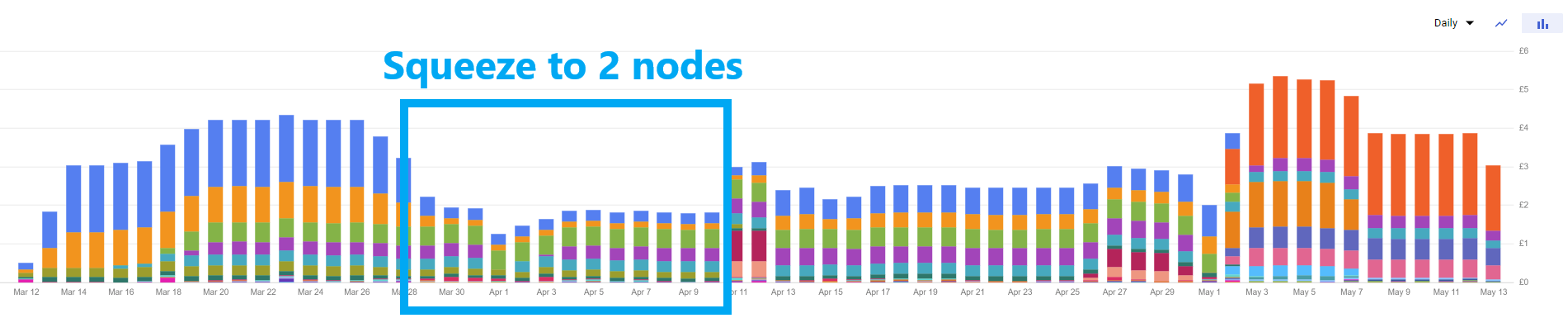
GCP Spend - 2 x Spot Nodes
The nodes ended up as a custom machine type still on Spot E2, as it was easier to squeeze the CPU than the memory (these apps can tolerate being throttled as they’re very low usage, but of course have minimum levels of memory that they need to function).
This worked for a little while, and as you can see was the lowest cost solution I achieved. However, crucially, the memory pressure created by the very tight tuning on some workloads did ultimately lead to scheduling issues - especially for the chunkier workloads such as the databases behind Plausible, which I self-host.
This instability is what led me to try one of GKE’s funkier features …
Nap Time Boys n Girls
Node Auto-provisioning can be enabled per node-pool, and various options exist to set the behaviour you’d like. With appropriate tuning of behaviour this ended up around 25% more expensive than my extremely-squeezed setup, but around 33% cheaper than the three-node rig I started with:
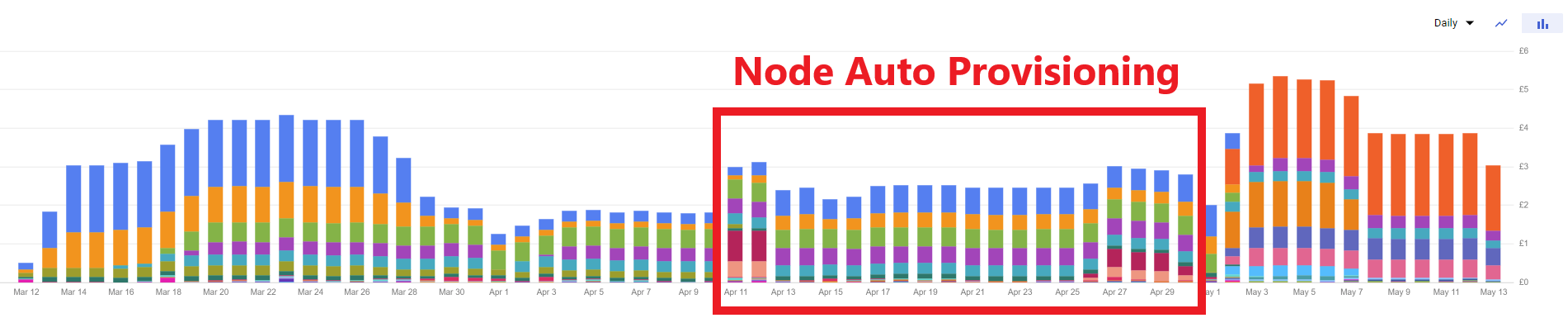
GCP Spend - Node Auto-provisioning + VPA
There’s a couple of points to elaborate on here:
- Enabling this via Terraform is straight-forward. The block below has most of what you’d need. You have the option of doing this at the cluster level or creating a NAP-enabled node pool alongside your existing, and using taints & tolerations to progressively move your workloads over to the new setup, based on risk. This is handy!
cluster_autoscaling {
enabled = true
resource_limits {
resource_type = "cpu"
minimum = "2"
maximum = "10"
}
resource_limits {
resource_type = "memory"
minimum = "10"
maximum = "20"
}
autoscaling_profile = "OPTIMIZE_UTILIZATION" # this makes turn-down more aggressive
auto_provisioning_defaults {
service_account = google_service_account.cluster.email
oauth_scopes = [
"https://www.googleapis.com/auth/compute",
"https://www.googleapis.com/auth/devstorage.read_only",
"https://www.googleapis.com/auth/logging.write",
"https://www.googleapis.com/auth/monitoring.write",
"https://www.googleapis.com/auth/monitoring",
"https://www.googleapis.com/auth/trace.append",
"https://www.googleapis.com/auth/servicecontrol",
"https://www.googleapis.com/auth/service.management.readonly",
]
disk_size = 30
}
}
-
Vertical Pod Autoscaling. Rather than continuing with my constrained Pod sizing, I enabled VPA for all workloads in “Auto” mode, which allows the pods to be restarted to set recommended sizes based on observed behaviour (none of these are on the JVM). I actually didn’t monitor this as closely as I thought I would beforehand (perhaps a future blog post on dashboarding this to come!), just trusting the system to do its thing. The graph above is the result of that.
- Rather than create
VerticalPodAutoscalerresources for each workload independently, I used Kyverno to generate these. That’s probably also a blog post in its own right, but here’s the snippet of policy to generate these, in case you find it useful:
- Rather than create
-
Some minor trickery is required to ensure that NAP nodes are scheduled as Spot Instances, for the saving. This is because you’re no longer in control of that from the cluster perspective, instead having to specify on the workload itself that it can tolerate being on Spot.
- I again used Kyverno for this, see this snippet (note that I also had to allow it target resources in
kube-systemfor this to remove all non-Spot nodes - Kyverno does not do this by default): - Fair warning - this policy wasn’t as foolproof as I’d like. If you look closely at the cost chart above, they rise slightly towards the end coinciding with the appearance of some dark red blocks - this is non-Spot Compute nodes appearing. I did not investigate this closely, but something to be aware of and/or alert for, if you use this extensively.
- I again used Kyverno for this, see this snippet (note that I also had to allow it target resources in
-
Finally, ensure that the safe-to-evict annotation - which I already had set - is present, to help the Cluster Autoscaler turn-down nodes containing pods with ephemeral storage. Again, Kyverno can handle this:
This worked well enough and I would’ve been content to stop here, but whilst I was trying out these sort of options, I felt I was in a good position now to try out Autopilot - GKE’s not-so-new option for going “nodeless” entirely.
Whose Node Is It Anyway?
Autopilot mode for GKE takes away configuration of the node pools entirely. This is an either/or situation - you need to build a new cluster to switch over to this, so needs careful implementation to move your workloads over to it.
You can see also from the graph below that this was not as cheap as the NAP option - settling into ~30% more after I had gotten the setup stabilised on Spot, in comparison to the fully-implemented NAP setup (you can see from the graph that it took me a little time to get things stable!):

GCP Spend - Autopilot
I set this up as a parallel cluster and then moved the workloads over to it bit by bit, due to some of the fundamental differences between Standard & Autopilot and not being willing to take the plunge on all at once. The terraform for the cluster is much simpler - enable_autopilot = true is the heart of it - running a plan will guide you into what’s incompatible in your remaining config. I found I could delete around 50 lines or so of config from the NAP-based one above. Result!
As well as the need to create a new cluster, some other things to be aware of with Autopilot are:
-
Autopilot has a minimum required CPU and Memory for a Pod as well as ratios between them - and it will raise the values to these as needed, depending on how you’ve configured your Pod spec. I’m sure this is why I ended up with a more expensive overall setup.
- One way you can reduce this is to removal any zonal anti-affinity rules you have set up - if you’re willing to trade-off against the extra resilience this affords you. This allows for lower minimum values to be used.
- I also chose to leave VPA enabled even though my assumption is that this doesn’t allow the pod to be resized below the minimum required for Autopilot 🤷
-
Autopilot itself doesn’t allow certain things, which may affect what you can run on it. See this document for more detail - privileged pods for example may be an issue if you’re using some weird-n-funky workloads (I used to run my Gitlab Runner out of GKE, which would’ve been an issue here if I wanted to use the docker-in-docker service, rather than kaniko).
I also chose to explicitly specify Spot in my Pod spec this time - based on the observation from the NAP setup not working perfectly via the Kyverno mutation. The docs recommend the following in your .spec.template.spec:
spec:
template:
spec:
nodeSelector:
cloud.google.com/gke-spot: "true"
terminationGracePeriodSeconds: 25
# ... rest of pod spec
Despite the moderate increase in cost, I was pretty happy with the outcome. It feels leaner and simpler to just simply “not care” about the nodes any more (see this list for example of the differences). I wouldn’t be concerned about reverting back to NAP, but for the small increase in cost, I felt the trade-off was acceptable. It also lines up with Google’s default behaviour going forward for GKE - I believe it became the default mode for new clusters from GKE v1.25 onwards.
It does make me wonder whether Kubernetes really benefited from exposing the underlying concept of
Nodein the first place - certainly in a cloud-provider world at any rate. Would it have been as popular as it is now? A good question to ask one of the original maintainers perhaps, if you were ever to find yourself in a room with them 😄
Conclusions
My conclusions from this (caveat: brief!) bit of experimentation?
If you really, really need to minimise the damage to your bank balance, and are willing to risk the impact to service availability by getting things wrong or pushing things too hard, then right-sizing your workloads and packing them as tightly as possible gets you the biggest saving.
If you want to lower your cognitive load, then just don’t worry about the nodes at all and enable GKE in Autopilot Mode. Check the feature compatibility needs against your workloads before doing so however, especially if you need to run privileged pods (ideally, you should not!). Even though the minimum pod spec sizes are generous for small apps, this seems to nearly balance out by avoiding the cost of “other stuff” on the node, but is slightly more expensive than you could achieve if you used …
… Node Auto-provisioning. This fulfils a nice sweetspot if you have workloads that need the full-fat GKE Standard features, but you don’t want to think about the Nodes that much. I combined this with Vertical Pod Autoscaling to right-size my Pods for me, combining with a fairly tight overall ceiling on the size of compute available so that I didn’t get a nasty surprise. Getting this configuration right out the gate is non-trivial, however.
And of course one final point - if you choose either of the automatic compute options NAP or Autopilot, be sure to follow the guidance on scheduling onto Spot Instances to maximise your savings - this is significant!