Team Nimbus and the Agents of Chaos
A post about my team’s first venture into running a Chaos Day — a series of chaos experiments against our platform
This blog post is about my team’s first ever Chaos Day - where we ran a series of experiments designed to test how our platform performed when we tried to disrupt it, or the workloads that run on it.
This entry was originally posted on Medium under my employer’s publication.
It was January 2020, and we had just gone through another Peak trading period - significant for a larger retailer. The Digital Platform had performed extremely well. There were no incidents, no last-minute panic scaling, and no fall-backs enabled — even though the number of services and overall complexity of the platform was significantly higher than this time last year. Not perhaps the backdrop to make a compelling case for running a series of complex operational test scenarios then? Well, we are not the sort to be resting on our laurels …

Bring the Chaos!
The term Chaos Engineering is not a particularly new one, but the benefits it can bring to an increasingly distributed and complex set of systems is significant. If you’re less familiar with the term, this blog post is an excellent primer, talking through its origins and some of the amazing work that the likes of Netflix Engineering do to pioneer these techniques, as well as what the numerous benefits can be when you do it well.
As a team we are striving to help uplift our teams to achieve better operability — it seems only right that we should hold ourselves to the same standard and test our own proficiency too!
Our platform code has a battery of automated tests, of course, but it is difficult to replicate every possible scenario or combination of events — we make implicit assumptions about the behaviour of our systems and in particular the behaviour of people involved. In other words, a bit of deliberately subversive thinking can potentially be very beneficial.
With that in mind, we started planning for our first Chaos Day before Christmas. Some of our colleagues had experience of doing this at other organisations, and this was helpful in giving us a framework for capturing ideas and structuring the day.
Our goals boiled down to four areas of learning:
- to learn how our platform team responded in incident situations.
- to test our own & other teams’ alerts and their responses.
- to learn how other teams experience failure and how they report it to us as a platform team for assistance.
- to learn how to run a Chaos Day with a small group of responders, before extending or scaling it out more widely as a practice.
Running the Day

Running the Chaos Day itself compromised six steps:
-
Visualise your system. In order to come up with effective scenarios, you need to understand how the system you are targeting behaves. We gathered all of our Platform Engineers in front of a whiteboard, drew a picture of the main components, and out came the Post-It notes! Tapping into the collective wisdom of the team generated a large backlog of ideas for us to explore further.
-
Next, you need to assemble a team of chaos agents. The prevailing wisdom here is to — especially for your first time doing this — go with experience. In other words, folks who’ve seen things go wrong, and know how they’d fix things if needed. Knowing how to reverse the effects of your test is very important! We opted for a team of three chaos engineers, supported by others on the day.

Chaos Agents Assemble!
- With your team assembled, it is time to capture the experiments. We followed guidance on how to structure these, which can be summarised as:
a. What is your test actually doing? b. What are you expecting to see in the system as a result? c. What are you expecting in terms of a response? d. How will you roll back if needed?
We threw these on a Trello board to make orchestration easier on the day itself. Each agent ended up with two experiments to run, plus a backup experiment to use if needed.
One of the hardest things when designing the experiments is not the initial idea, but coming up with a way to reproduce the conditions you are intending. In modern systems, you can rarely just “pull the plug” or simulate strange behaviour downstream in a realistic way. Next time, hopefully we’ll be armed with some additional tools to help with this too.
-
Agree a date, and send comms to teams. We didn’t want to just spring it on people, but we did choose a “normal” day, rather than, say, running it on a Friday or early in the morning/evening. After all, we are testing the behaviour of people as much as the system, so wanted things to feel realistic.
-
Co-locate your chaos agents, and start b̵r̵e̵a̵k̵i̵n̵g̵ ̵s̵t̵u̵f̵f̵ experimenting. Our timeline of the day, at a high level:
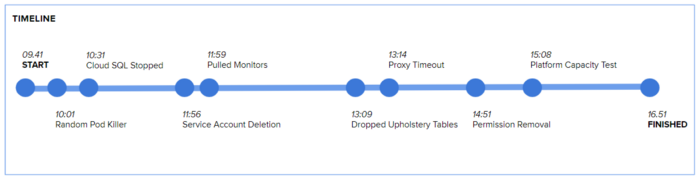
Some tests were allowed to overlap, as they affected different areas of the platform
Having a timeline for the day is important — you want to think about the potential effect of overlapping tests in particular. Seeing what happens when folks are at lunch is fine, but tearing down servers while you’ve also pulled the plug on the monitoring tools is a bit harsh!
Being in the same room is important not just because of the snacks 😉 but because we could each help each other out with our tests — either through mutating the tests to be more effective on the fly, or helping watch the behaviour of responders while a test is going on. We were lucky enough to have a few other interested folks in the room, helping with this aspect (and sworn to secrecy of course!), as well as making sure things were running smoothly in general.
We ran eight experiments on the day, six of which were planned. The extra two “on the day” tests were based on the behaviours we were seeing at the time. We deliberately tested only in Non-Production, as this was our first time doing this and we needed to practice the process (see Trap 5). We supplied a steady low load through the environment to make it appear more live-like for teams.

- Learn from it. This is the most important aspect, otherwise there is no point in doing it! We saved transcripts and screenshots during the day (Slack was amazing for this), chatted to responders afterwards (either individually or in a retro), and wrote up the effects of our experiments in a style similar to a post-incident review (but lighter weight). We’ve also run showcases for our wider tech community, as well as this blog post!
We’ve seen teams raise & complete operability tasks on their backlog as a result of our testing, as well as surfaced some gaps in knowledge that have prompted a shift in priorities. We also feel more confident in running one of these again soon.
The Tests Themselves
Below are examples of a couple of the tests we ran, and our learning from them, to bring this to life.

Data is hard
For one of our tests, we stopped and later on deleted the data in a relational database that powers one of our customer-facing features on the website. Whilst a relatively unlikely scenario in normal running, human beings make mistakes, and this process was designed to test the response mechanisms to deal with this scenario.
What did we learn?
- We had gaps in our alerting to identify the underlying causes, although alerts did fire for an availability breach in the overall service itself.
- We provide instructions to our teams on how to recover their data, but didn’t actually give them permission to do the restore — this resulted in a need to call the platform team. Oops!
- The Tech Lead for the team affected was instrumental in resolving the issues. It would be interesting to repeat this test when he was on holiday — especially when you don’t have a runbook … 😉

Don’t forget your legacy
We have two versions of our digital platform (imaginatively, v1 & v2) — both run critical components — but v1 is older and changes more infrequently. One of our tests broke a component that runs in both. Our engineers spotted and fixed the issue in v2 very quickly ⭐. But what about the legacy platform?

What did we learn?
- One of our platform engineers is too good at fixing problems — guess who is going to be a chaos agent next time … 😁
- If you are relying on confidence in your alerting to pick up on problems, you need to make sure they have coverage of your older systems too, not just the shiny new stuff you work on day-to-day.
- Older components that are heavily used, but not necessarily actively worked on or owned by a single team, creates a lot of confusion when they break.
- When a component has a reputation for being generally unreliable, people make assumptions that the situation can be ignored (i.e. alert fatigue).
- When an incident earlier in the day was attributed to one service/team, people make assumptions that subsequent issues later in the day are related to the same thing.
- Maintaining engineers’ knowledge of code they don’t work on regularly is very hard — better to eliminate your legacy than carry this risk, perhaps? 😏
Asking for help and trusting the source
Later in the day we ran an experiment inspired by an outage in Grafana Labs to consume compute resources through a combination of high requests and Pod priorities. The configuration change was subtle, but the issue was reverted by identifying the misbehaving component and re-executing its deployment pipeline — this effectively restored the component in question to its default (intended) settings.
The nature of the test (consuming lots of resource on the Kubernetes nodes) meant that, until identified and resolved, the larger workloads on the platform were taken out of service — this happened to be our telemetry tooling (Prometheus) and part of our CI/CD tooling (the GitLab runners). The blast radius for these, especially in Non-Production and when other tests are going on, is high.
In addition, we had another experiment running at the time: we’d revoked a couple of our engineers’ access to the platform. This was effectively an untested scenario — there’s no runbook for this one — and assumptions are made when onboarding new team members that certain people are around. What does your escalation path look like if they aren’t available and it’s an emergency?

What did we learn?
- Infrastructure as code, with automated pipelines that you trust as the source of truth, is a powerful mechanism to restore service.
- When looking after critical systems, it’s important to know when to ask for help from your teammates, and what your escalation routes are if you need them.
- Taking out shared components, such as CI/CD infrastructure or telemetry tools, whilst other experiments are going on is particularly evil 😈. Should we segregate the components required to diagnose and restore service from the workloads in question?
- Don’t taunt the chaos agents!

Overall Reflections
We felt that this first foray into running a Chaos Day went really well — it was a lot of fun and we learnt a lot! Teams involved in responding to the experiments dealt with the scenarios very effectively on the whole, and any experiments that took a long time to be picked up, tended to be where responsibilities were unclear. From a systems perspective, our observability tools, alerting and communication mechanisms for teams worked well.
It was clear that being a responder to these tests — especially on multiple experiments in a day — is exhausting, much like responding to a real incident.
The experiments we ran against our older “legacy” components of the platform were the ones that took longer to spot and resolve. As we’ve evolved our platform to meet the needs of newer products, the components we’ve left behind on the older version of our platform have suffered — they work, but they’re less well-understood because they’re not being as actively developed. This has helped us justify making the time to draw down on the larger pieces tech debt.
There were also a number of learnings at a practical level, such as gaps in alerting, missing runbooks, and incorrect permissions — these should be straightforward to address. It will be interesting to see whether the more of these sessions we run, the fewer examples like this we find.
What Next?
We do it again! We felt this was valuable enough to be worth running again, extending the number of things we break, and covering a wider range of services and teams.
Our broader goals include making this a facility that teams feel confident doing themselves, perhaps with assistance in getting started, and eventually moving the testing into Production too.

We need to prove that the above is not how we think about things any more!