KubeCon - Other Cool Things
Some of the other tool things I learnt at KubeCon that don't fit neatly into other posts!

Yes, this was a wall of donuts to celebrate Kubernetes 5th birthday!
I’m going to use this blog post to talk about a couple of other things I learnt about while at KubeCon 2019. These don’t slow neatly into my other posts from my time at the conference, but I still felt they were interesting enough to call out separately.
How Changing Kubernetes Itself Works
I went to a couple of talks focusing on some proposals for improving Kubernetes itself. As well as liking the content being proposed, it was interesting to learn a little bit about how the process of making changes to Kubernetes - what is a giant open source behemoth now - actually works.
M-M-M-M-Multi-Cluster Ingress
The first of these was about ingresses from a couple of Googlers - Rohit Ramkumar & Bowei Du. I do enjoy a good load balancer talk, I do. Topics included:
- Should we even have ingresses at all?
- Assuming yes, how portable, extensible, featured should it be? The current one has been dumbed down to ensure it’s portable - at what cost? They actually got divisive responses from users when they surveyed on this topic too
- What are others doing - in particular Istio & Contour by the sounds of it
In the end, they are essentially proposing two new kinds - MultiClusterIngress and MultiClusterService. Both sound very sensible, and are modelled on existing primitives, but with the typical stuff you include nested within a template, allowing for the extension to also include things like cluster.select.matchLabels(region=eu) or similar. There’s also mention of being able to route to storage bucket (do want!!).
They are deliberately trying to minimise how opinionated they are - allowing ingresses to use Extended or Custom APIs on top, such that users can trade off portability for feature-set if they wish to.
It’s early days so may take some time to hit prime-time, but it was very interesting to learn about their thought processes and the direction things are (probably) heading - it’s still a draft for a proposal at present.
Dynamic Autoscaling (and Cake)
At the moment, Kubernetes is limited. No way! Well, about this specific thing it is. The PodSpec is immutable, which means if you want to dynamically set your resource requests or limits, you’re SOL unless you’re ok with restarting your pod. And who wants to do that? This is not so great when you have an app that has daily/weekly/seasonal patterns of use, steady growth of user base, varying app lifecycles, and so on.
So, this talk was about, well, umm, changing it to be mutable instead. Sounds simple enough, right?
Well apparently doing that sort of thing ain’t so simple - there’s loads of code in the Kubernetes Core (in particular, the Scheduler and Kubelet) that assume it is.
At the moment, the Vertical Pod Autoscaler will both recommend and (if you enable it) recreate your pods based on its sizing recommendations. This change would allow it to do this without restarting them. For certain kinds of pods (not Java, /sigh). Still, we have other stuff too that could benefit from this. And I’m sure at some point we’ll rewrite everything in Golang when Google’s completely taken over the world. Or if they don’t, then maybe Rust?
If you’re wondering why we aren’t using it already - I think it has a lot to do with our workloads not being bound by the obvious stuff like CPU and memory. We’d need to spend some time working out the best (custom) metrics to use as the scaling measure, and we’re just not at the scale where it’s worth doing that yet.
Intuit, Argo & The Custom Deployment Controller
I really want to give a special mention to Intuit (of finance/accounting software fame). They had a couple of their engineers (Danny & Alex) on stage talking about a customer controller they’ve created and open sourced (to a big round of applause - lovely!).
So, why did they write their own controller? Well, they have a pure GitOps philosophy going on, and really wanted their deployments to follow that methodology - even when their development teams were making use of things like Blue/Green and Canary deployments. There’s no built-in approach in Kubernetes to follow these sort of techniques.
Their story started with Jenkins (long list of problems), via some Deployment hooks (not transparent for engineering teams) - neither of which were truly declarative for these style of deployments. So, they did it themselves. They liked the Controller pattern because it codifies the orchestration, can be built from the ground up to match their approach, runs inside their cluster for easier identity management, and allowed them to make the migration path smooth for teams by iterating on the standard Kubernetes constructs (i.e. a Deployment), with just a couple of tweaks to their yaml.
6 months later, they launched this: https://github.com/argoproj/argo-rollouts. It takes care of things like ReplicaSet creation, scaling and deletion - just like a Deployment, with a single desired state described in the PodSpec, supporting manual and automated promotions and the use of HPA.
They showed a couple of example yaml files to illustrate the difference from a Deployment, which are minor. Besides the obvious adjustments to the apiVersion & kind at the top, you add a strategy stanza, such as:
strategy:
blueGreen:
activeService: active-svc
previewService: preview-svc
previewReplicaCount: 1 # optional
autoPromotionSeconds: 30 # optional
scaleDownDelaySeconds: 30 # optional
… for Blue/Green (note the pre-canned active & preview environments, and some toggles), or Canary:
strategy:
canary:
maxSurge: 10%
maxUnavailable: 1
steps:
- setWeight: 10 # percentage
- pause:
duration: 60 # seonds
… which feels a lot more like a Deployment with its more transient environment and no service modification.
They do a demo, which I have to say looks super-whizzy - they use ArgoCD for their tooling and it has some lovely visualisations. I really liked how it detected and displayed the changes to the Service/Pods in real-time - great for radiator dashboards (rather than kubectl get pods -w). There’s also a traffic flow visualisation showing the traffic split between blue and green (… in blue or green arrows). Slick.
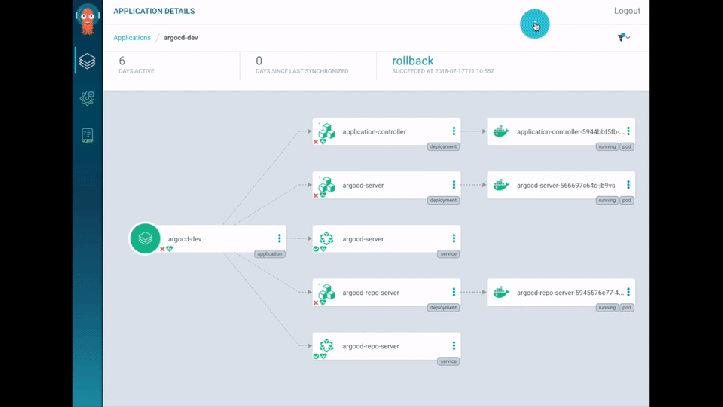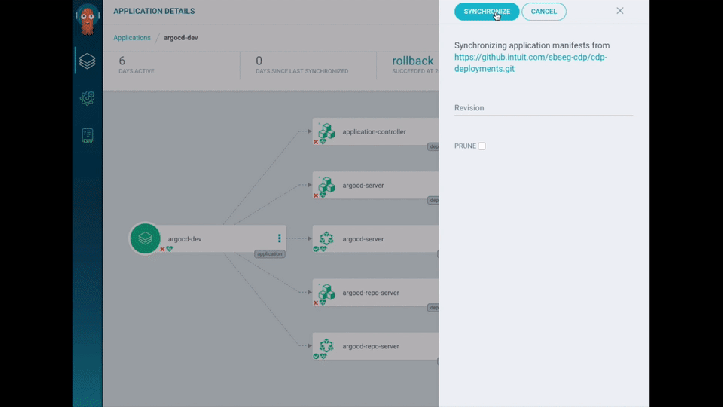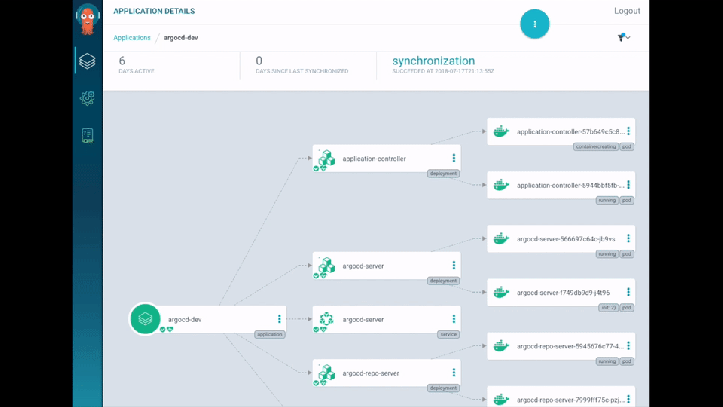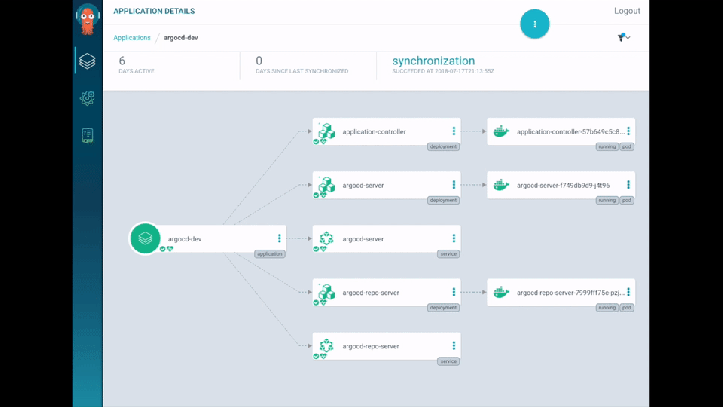
As an aside, I popped by the CodeFresh booth while at KubeCon, which also had something similar
They’ve still got some work to do - for example they’re interested in Service Meshes to avoid the need for a large number of replicas for Canary (the classic “I need 10 pods to do 10%”) and other deployment strategies to support experimentation, A/B testing, etc.
All in all, really impressed with their talk and the things they’ve achieved here. Very cool!
Compliance as Code
In some of the specialist tracks I went to, I learnt several other interesting things too.
For example, I started the day learning about some proposals around a Multi Cluster Ingress - Ingress v2 basically (yes please, looked great!), an intro to SPIFFE and SPIRE (which sounded useful but a bit early-days for folks like us, perhaps), some wildly sensible folks from Lyft & Triller talking about permissions options in Kubernetes (reassuringly, we are doing a lot of things in this space already - I did learn some funky things about Admission Controllers and Open Policy Agent though).
The latter inspired me sufficiently to go to a more thorough talk on Open Policy Agent Gatekeeper at the expense of some other interesting stuff - presented by folks from Google & Microsoft. It works through a set of CRDs so feels more config-y than code-y - although there is code buried in the templates you produce. This sounds like something we should get into - it’s only in Alpha at the mo. They worked through a demo of four policy enforcement use-cases:
- All namespaces must have a label that lists a point of contact
- All pods must have an upper bound for resource usage
- All images must be from an approved repository
- Services must all have globally unique selectors
These sort of things sounds highly relevant to me. I know our team have tried it out a bit and been put off by the Rego language, but I understand that the tooling support for this is improving considerably, and as the popularity of OPA increases, examples of how to do this well will make our lives easier in this area anyway. They’re definitely shooting for making it easier to write, test, automate into pipelines, and re-use - all good things I like to hear!
Most importantly, I learnt that we should be pronouncing it “Oh-pa” not “Oh-Pea-Ay” … +1 for more pronunciation guides. Now that’s a valuable reflection right there.
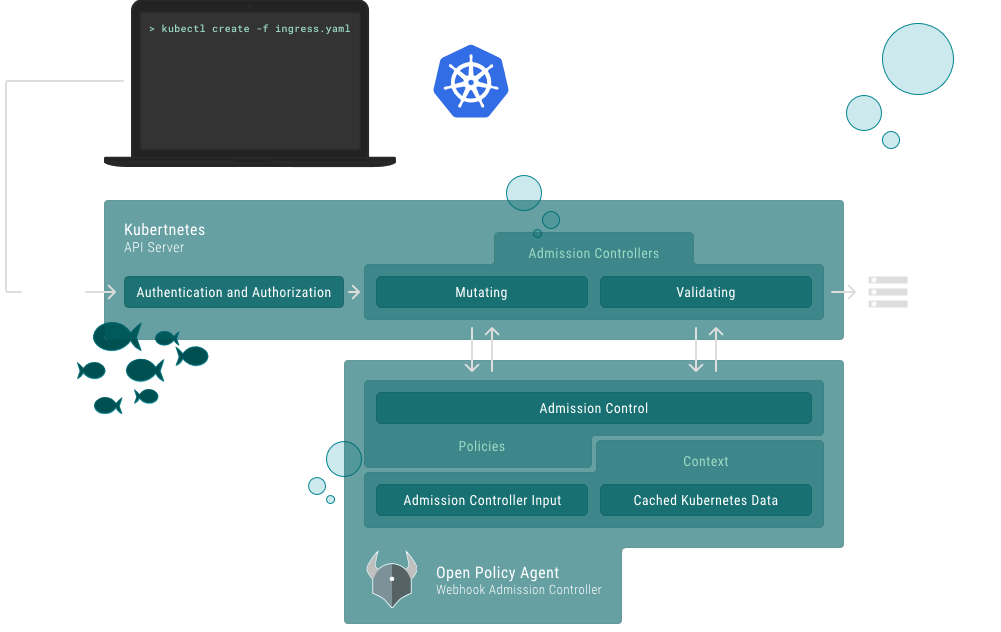
OPA Architecture, from their website
Kubernetes Failure Scenarios
One of the more technically deep sessions I went to was by Datadog (Laurent Bernaille & Robert Boll) of monitoring tools fame. Their talk was on a top 10 of “surprising” Kubernetes failure scenarios.

They run a very large fleet (biggest cluster has 2k nodes, they average 1-1.5k) - for comparison ours are less than 100 …
I’ve summarised this down massively, if you’re interested in the detail, be sure to check out their talk online:
- It’s
neveralways DNS. Gets a round of applause! 😁 - Image Stampede. Pods in CrashLoopBackoff with
imagePullPolicy: Alwayswhen your image registry sits behind some NAT instances can cause your whole registry to get blacklisted - “I Can’t kubectl”. Crashing the apiserver by accidentally deleting a node selector so that a search was running over the entire cluster rather than a subset
- Pods not scheduling. Tight limits on resource quotas being accidentally breached by a DaemonSet that was supposed to not have them set. Pod Eviction due to this being a critical PodPriority also!
- Log intake volume. They basically DDoS’d themselves by enabling audit logging on a DaemonSet
- Where did my pods go?. A subtle bug after enabling
HorizontalPodAutoscalerwhen removing the hard-coded number of replicas - you also need tokubectl editto remove an annotation at the time you remove this to avoid the Deployment reseting replica count to 1. - There’s a ghost in Cassandra. Their cloud provider being a bit too smart - lack of capacity in a preferred AWS Availability Zone resulting in new nodes being scheduled in another, and then moved back when the capacity was freed up - detaching the pods from their AZ-bound disk.
- Slow deploy heartbeat. A misconfigured CronJob which couldn’t be placed on a node causing every loop of the scheduler to try to place it on one of 4,000 pods.
- “We expect containers to be contained”. Various examples of dodgy container behaviour, including zombie threads to a readinessProbe with an exec being too slow for the timeout, one due to a low level disk blocking issue, and another due to slow slow pod startup from excessive I/O from DNS, audit logs and kubectl API calls. They use pools per app (with taints and tolerations) to truly contain their workloads. That’s pretty scary to me!
- “Graceful” Termination. Constraints caued by long-running jobs - beyond the length of kubelet restart for example, due to batch-y workloads.
Their key takeaways were:
- Careful with DaemonSets in large clusters
- DNS is hard
- Cloud infrastructure is not transparent
- Containers are not really contained
All The Sessions I Went To
If you’re curious what sessions I went to, here’s a full list, with video links:
Playlist with every single session from KubeCon - see you next year!
Tuesday
- Keynote: Stitching Things Together – Dan Kohn, Executive Director, Cloud Native Computing Foundation
- Keynote: 2.66 Million - Cheryl Hung, Director of Ecosystem, Cloud Native Computing Foundation
- Keynote: CNCF Project Update - Bryan Liles, Senior Staff Engineer, VMware
- Sponsored Keynote: Network, Please Evolve – Vijoy Pandey, VP/CTO Cloud, Cisco
- Ingress V2 and Multicluster Services - Rohit Ramkumar & Bowei Du
- Intro: SPIFFE - Emiliano Bernbaum & Scott Emmons, Scytale
- Fine-Grained Permissions in Kubernetes: What’s Missing, and How to Fix That - Vallery Lancey, Lyft & Seth McCombs, Triller
- Intro: Open Policy Agent - Rita Zhang, Microsoft & Max Smythe, Google
- The Multicluster Toolbox - Adrien Trouillaud, Admiralty
- Keynote: Welcome Remarks - Janet Kuo, Software Engineer, Google
- Sponsored Keynote: Democratizing Service Mesh on Kubernetes - Gabe Monroy, Microsoft
- Keynote: Kubernetes Project Update - Janet Kuo, Software Engineer, Google
- Sponsored Keynote: Recursive Kubernetes: Cluster API and Clusters as Cattle - Joe Beda, Principal Engineer, VMware
- Keynote: Reperforming a Nobel Prize Discovery on Kubernetes - Ricardo Rocha, Computing Engineer & Lukas Heinrich, Physicist, CERN
- Sponsored Keynote: Expanding the Kubernetes Operator Community - Rob Szumski, Principal Product Manager for OpenShift, Red Hat
Wednesday
- Keynote: Opening Remarks - Bryan Liles, Senior Staff Engineer, VMware
- Keynote: How Spotify Accidentally Deleted All its Kube Clusters with No User Impact - David Xia, Infrastructure Engineer, Spotify
- Sponsored Keynote: Building a Bigger Tent: Cloud Native, Cultural Change and Complexity - Bob Quillin, VP Developer Relations, Oracle Cloud
- Keynote: A Journey to a Centralized, Globally Distributed Platform – Katie Gamanji, Cloud Platform Engineer, Condé Nast International
- Sponsored Keynote: What I Learned Running 10,000+ Kubernetes Clusters - Jason McGee, IBM Fellow, IBM
- Keynote: Debunking the Myth: Kubernetes Storage is Hard - Saad Ali, Senior Software Engineer, Google
- Keynote: Closing Remarks - Bryan Liles, Senior Staff Engineer, VMware
- Monitoring at Planet Scale for Everyone - Rob Skillington, Uber
- Resize Your Pods w/o Disruptions aka How to Have a Cake and Eat a Cake - Karol Gołąb & Beata Skiba, Google
- Benefits of a Service Mesh When Integrating Kubernetes with Legacy Services - Stephan Fudeus & David Meder-Marouelli, 1&1 Mail & Media
- Reinventing Networking: A Deep Dive into Istio’s Multicluster Gateways - Steve Dake, Independent
- Deep Dive: Cortex - Tom Wilkie, Grafana Labs & Bryan Boreham, Weaveworks
- 10 Ways to Shoot Yourself in the Foot with Kubernetes, #9 Will Surprise You- Laurent Bernaille & Robert Boll, Datadog
Thursday
- Keynote: Opening Remarks - Janet Kuo, Software Engineer, Google
- Keynote: Kubernetes - Don’t Stop Believin’ – Bryan Liles, Senior Staff Engineer, VMware
- Keynote: From COBOL to Kubernetes: A 250 Year Old Bank’s Cloud-Native Journey - Laura Rehorst, Product Owner - Stratus Platform, ABN AMRO Bank NV & Mike Ryan, DevOps Consultant, backtothelab.io
- Keynote: Metrics, Logs & Traces; What Does the Future Hold for Observability? - Tom Wilkie, VP Product, Grafana Labs & Frederic Branczyk, Software Engineer, Red Hat
- Keynote: Closing Remarks - Bryan Liles, Senior Staff Engineer, VMware & Janet Kuo, Software Engineer, Google
- DIY Pen-Testing for Your Kubernetes Cluster - Liz Rice, Aqua Security
- Grafana Loki: Like Prometheus, but for Logs - Tom Wilkie, Grafana Labs
- Deep Dive: Linkerd - Oliver Gould, Buoyant
- How Intuit Does Canary and Blue Green Deployments with a K8s Controller - Daniel Thomson & Alex Matyushentsev, Intuit
- Delivering Serverless Experience on Kubernetes: Beyond Web Applications - Alex Glikson, Carnegie Mellon University