KubeCon - Reflections
KubeCon 2019, Barcelona - my reflections on the conference as a whole

Barcelona night skyline - taken from Riot Games’ website
This blog post summarises my thoughts on a very entertaining and informative trip to KubeCon + CloudNativeCon in Barcelona, May 2019. It was my first trip there and I picked up a variety of useful bits ’n’ pieces while I was there.
Any Stand-out Themes?
In trying to sum things up, I find myself struggling for any stand-out themes. Thinking about this a little more, I reckon this is probably a fairly natural thing to happen when comparing to “big vendor” conferences where they have large product & marketing teams driving their goals. Here, however, is a community event of largely open source software. Even the larger commercial vendors embrace the spirit of it all. It’s actually really refreshing.

One personal theme I do reflect on is how nice it is to actually hear from real customers and users of this stuff. Sure, I went to a few talks from the big tech companies, but even then they’re presenting very experience-focused content; their speakers are focusing on how they’re engaging with the community as a whole, and so on. Not at all sales-pitch-y. It’s pretty brilliant.
It’s clear that the community around these technologies, with Kubernetes at its foundation, is vibrant. This is fantastic for the future of these sort of services, and it’s also pretty clear to me that this is at least in part because the people behind it are working very hard on promoting this attitude.
As I work with - and am hopefully seen as someone who helps set the direction for! - a set of “platforms” teams, it was very reassuring to hear from several other end-users of this tech in the enterprise, all approaching things in more or less the same way that we have chosen to. This was definitely a community of platform builders using these tools as the raw blocks to build even better platforms tailored for their own users (software developers).

Many of these organisations also seem to have started from a place similar to ourselves (“I need to go faster”, “I need to put more powerful tools in the hands of our engineers”) and they continue to face the same sort of challenges we do (“how do I choose which option to go with?”, “how much do I do / get others to do / leave to engineers?”). The fact that we’re not alone in the problems we’re facing is one of those unfortunately reassuring things.
And of course, the onus is on us to continue to keep solving the next challenge and the challenge after that - and to make sure we stay on top of the best ways of building platforms so it doesn’t become stale and ineffective. A trap we’ve fallen into in the past.
The Higgs-Boson
The personal highlight for me was actually - perhaps awkwardly! - nothing to do with helping me in my day-to-day job 😁 I think I just enjoyed it due to how effectively it promoted these technologies as a positive force, combined with the fact that it plucked at the long-ago-sadly-largely-forgotten chords of my time as a scientist.
It was during the keynote at the end of the first day, watching a software engineer + physicist from CERN on stage in front of 7,000 people run a live demo that recreated the analysis used to detect the Higgs-Boson particle.

Higgs-Boson CMS Experiment - Kit
This was pretty sweet stuff. The scale of the physical experiment kit, the need to basically take a photo of a particle that disappears in a billionth of a trillionth of a second (actually, I think they take a photo of the after-effect of this) - it’s both staggering and fascinating.
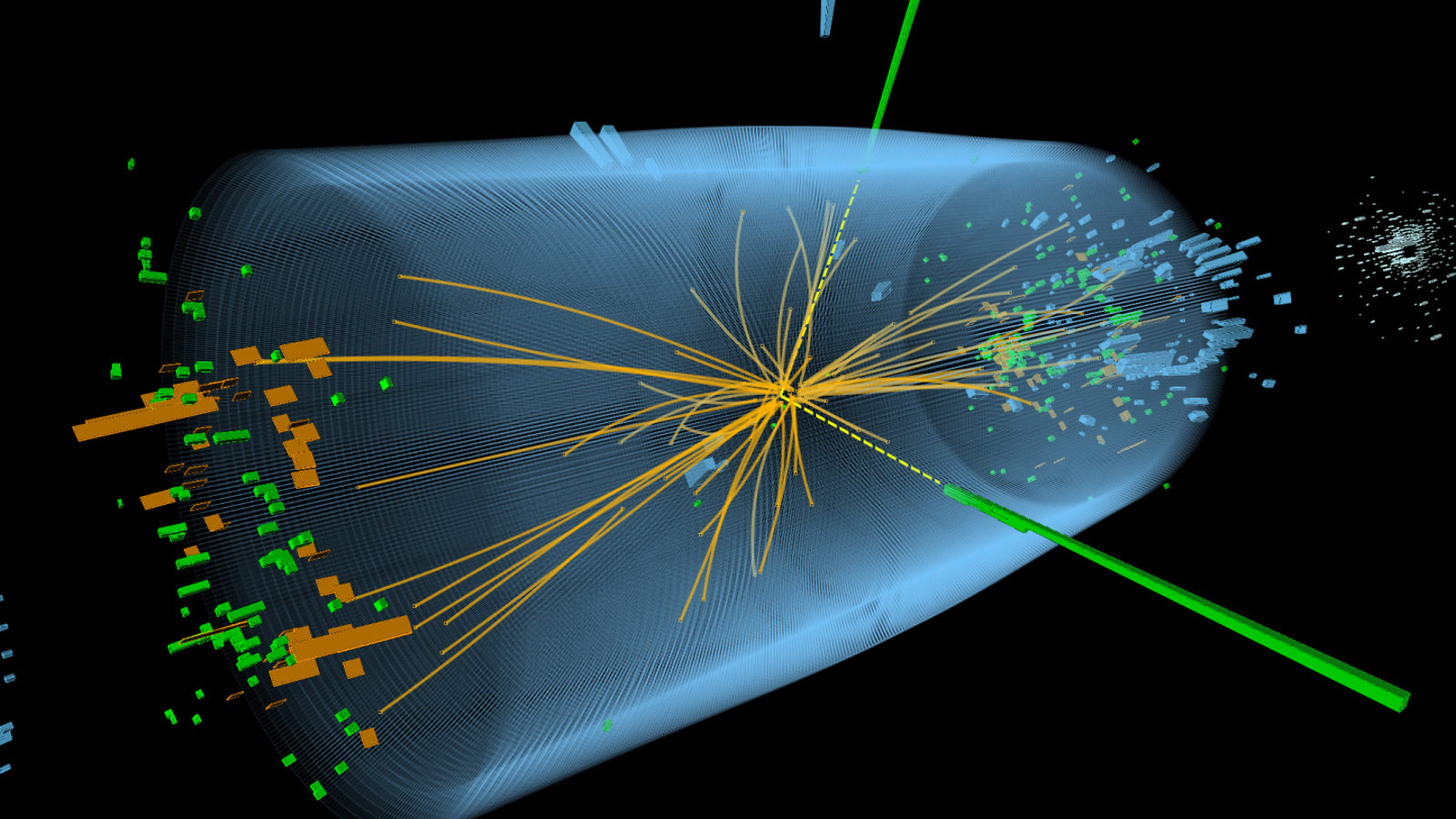
Higgs-Boson - Decay Model
Perhaps more incredibly, the computing is actually more mainstream (for this audience, at least), than I thought. Just a lot of it! They have 70Tb of data across 25,000 files, running across a Kubernetes cluster with 20,000+ cores. They use Ceph, and Redis, and Jupyter - stuff I’ve heard of and in some cases fiddled around with.
Funnily enough CERN wouldn’t let them borrow their actual kit for a demo - so instead they called in a favour from Google to run it on GCP instead. Yay Public Cloud!
This turned out to be a great advert for Google - we see them bursting up to 180Gb/s pulling from Object Storage which is crazy rapid. It does make you wonder, given they’re running this on GCS + GKE - how are they mounting that object storage to get those speeds?!
To recreate it in an authentic fashion, they use the data from the experiment itself, and the software used back then (2010 - go-go-gadget Docker) - despite this they’re returning a successful result in just a couple of minutes.

Inspector Gadget. I loved this as a kid!
Apparently anyone can do this as the data & source code is public - I wouldn’t fancy paying the GCP bill though 😉
This Kubernetes Thing Might Catch On
It was really nice to hear so much positivity about Kubernetes, the project that started this whole thing - which turned 5 years old at roughly the date of this conference. There were a few nods to this around the conference centre.

During one of the keynotes, Janet Kuo did a very nice segment on the Kubernetes project in CNCF itself. I liked her timeline narrative:

Uh oh, the Borg!
- 2003 - Borg was created. No, not in Star Trek, this is Google’s collective instead. That was, staggeringly enough, May 1989. Oh man now I feel old
- 2006 - cgroups arrived (Linux Control Groups => process containers)
- 2008 - Linux containers adopted the “container” naming
- 2009 - Omega - next-gen Borg at Google => influences Kubernetes design
- 2013 - Docker. Hooray for Docker, it’s the best
- 2013 - Project 7 (within Google, open source container orchestrator - comes from Seven of Nine from Star Trek of course - the Friendly Borg)
- 2014 - Kubernetes announced at DockerCon. There was much rejoicing
- 2015 - v1.0 of Kubernetes, CNCF formed, 1st KubeCon at end of year
- 2016 - SIGs came into being, KubeCon EU, industry adoption, in Production, at scale. This thing is a big deal
- 2017 - CRD introduced so can build your own Kubernetes resources on top of it. Kubernetes becomes a platform for building platforms (if Kelsey Hightower had a pound for every time that was mentioned at this conference …). Cloud adoption drives Kubernetes to become a de facto standard, many new native APIs introduced
- 2018 - Graduated from incubation in the CNCF. This is seen as a “stable in Production” thing
- Today - one of the highest velocity open source projects. It is number 2 on Pull Requests on Github (behind … Linux), #4 on issues/authors (out of 10’s of millions)
Now it is v1.14 and the most stable and mature ever. And hell you can even run it on Windows nodes. Now that is crazy.
It was also great to be reminded of the Kubernetes Comic Books (I picked up a copy - yay) - I didn’t realise there were two of them!

Service Meshes

Photo by Ricardo Gomez Angel on Unsplash
Service Meshes have always been an interest for me since I first learnt about the concept in more detail at Google’s Next conference last year. Up until now I’d always assumed that Istio would be our answer to that - running on Google Kubernetes Engine after all, and Google are the main contributor to Istio - but I used the opportunity at KubeCon to learn a bit more around the topic.
First there was the introduction of SMI (Service Mesh Interface). The announcement was brief, but welcome - having these things start to coalesce around a standard can only be a good thing.
I also listened to 1&1 talk about some of the challenges they’d experienced with Istio which mimicked my own, and took in a talk on an alternative mesh technology, Linkerd, which I liked the sound of and am tempted to try as an alternative. That said, my suspicion is that, in the end, we’ll still end up on Istio due to the richer features and fast-moving development resolving some of these challenges before we get round to needing it.
If you’re interested in an elaboration on these points, check out my other post here.
Observability

I also deliberately took in a number of talks on observability tools - in large part because it’s an area of focus for my team at the moment. Over here, you can read my more detailed thoughts on this topic.
We actually have three different angles on this:
1. Prometheus at Scale
We have an emerging scaling problem with Prometheus. At the moment, our Promethei are relatively small but still by far the biggests pods we run and occasionally perturbed by increases in usage and their standalone nature feels wasteful and limits us to only holding data for (I think) 45 days. Teams want to keep it for longer, which is not unreasonable in my view - we need to do better.
I therefore was particularly interested to learn more about M3, Cortex and a little about Thanos as open source solutions to this particular challenge.
2. The Logging Problem
Logs are useful to debug problems. They’re also in my view a trap for metrics to go into. We are doing a really good job lately at avoiding the latter, but that doesn’t mean we can continue to get away with providing our engineers with sub-optimal tooling for log analysis.
We already know about the Elastic Stack, but I went to a talk on Loki just to see what that was about and I liked what I heard - “built for engineers to solve problems” in particular - but it’s just too early days I think for us to gamble on it. Probably. Maybe. We will see.
It was also interesting to observe how crowded the booths for Elastic, Loki, Logz.io and DataDog were. Or maybe folks just wanted the stickers …
3. Distributed Tracing
We are pretty close to needing to provide some sort of distributed tracing tool in my view. We are doing microservice-y things and we are at the point now where those microservices are a little less customer –> microservice –> legacy and a bit more customer –> microservice –> another microservice –> oh and maybe another microservice too –> eventually legacy.
So the news that the two main open source ways of instrumenting that stuff - OpenTracing & OpenCensus - are joining together in a backwards-compatible way is very pleasing indeed.
I hope I’ll have an excuse to write more about this topic soon once I’ve got hands-on with some of the tooling in this area.
Wrap Up
And that wasn’t all either - I went to some other really interesting specialist tracks, including a couple of sessions on Open Policy Agent & Gatekeeper (which I think we should use!), Multi-Cluster Ingress, dynamic pod autoscaling, a Custom Deployment Controller, plus some weird and wonderful Kubernetes failure scenarios. For more details on these, see my Other Cool Things post.
All-in-all, it was a really fantastic conference with loads and loads of technical depth on an incredibly diverse platform ecosystem which is supported by an active and enthusiastic community.

Party time at KubeCon!