Squeezing GKE System Resources In Small Clusters
Trying to create as much usable Compute in a tiny GKE cluster as possible, by squeezing its system resources

Spoiler Alert! This blog is really about Vertical Pod Autoscaling and patching of kube-system workloads in GKE. It just might not sound like it at the start 😄 If you’re not interested in how I got there and just want to jump to the good stuff - I’ve summarised it at the bottom of the post.
So, this all started because I wanted to try out Elasticsearch. I’m not the biggest fan of GCP’s Stackdriver Logging, and I wanted to poke around with some alternatives. I have a “personal” GKE cluster that I use to run a few websites (including this blog!), and where I also experiment with these sort of things outside of work. Should be straight-forward I thought to myself. Sure, Elastic is Java - but I don’t need it to do that much, I’ll just shrink it down enough that it’ll start up ok, play around a bit, and then maybe see if I want to do more with it or sign up to a managed logging service instead.
Well, I was dead wrong about that! I quickly realised that there’s no way it was going to fit - even with only a collection of tiny workloads, too much of the machine resources were gobbled up by things running in kube-system and I really didn’t want to extend beyond my 3 x g1-small instances if I could possibly help it.
So, while I could make them temporarily larger while I experiment (yay Cloud), where’s the fun in that?! What follows is a look at what’s using up those resources and how I can shrink them down to smaller sizes - because let’s be honest, the handful of services I run on my GKE cluster aren’t going to need them to do a huge amount.
So, What’s Going On?
Visualise the Problem. No, not some sort of zen meditative technique. What are we actually dealing with here? Surely a dozen or so deployments of tiny web-apps isn’t gobbling up 3x1.7Gb? As with all things in life, we start with bash:
kubectl get po $1 \
-o custom-columns=NAME:.metadata.name,CPU_REQ:.spec.containers[].resources.requests.cpu,CPU_LIMIT:.spec.containers[].resources.limits.cpu,MEMORY_REQ:.spec.containers[].resources.requests.memory,MEMORY_LIMIT:.spec.containers[].resources.limits.memory
I later discovered
kube-capacitythroughkrew, which is a neater way of doing this
This ugly-as-hell one-liner produces something that looks a bit nicer than you’d think:
[~ (⎈ |mw-prod:default)]$ get-pod-resource-requests.sh kube-system
NAME CPU_REQ CPU_LIMIT MEMORY_REQ MEMORY_LIMIT
event-exporter-v0.2.5-7d99d74cf8-9jdn4 <none> <none> <none> <none>
fluentd-gcp-scaler-55bdf597c-xsxwr <none> <none> <none> <none>
fluentd-gcp-v3.1.1-6r6x5 10m 100m 100Mi 250Mi
fluentd-gcp-v3.1.1-mzgdn 10m 100m 100Mi 250Mi
heapster-v1.6.1-5b5df74474-vjvhd 13m 13m 120Mi 120Mi
kube-dns-6987857fdb-42kzx 100m <none> 70Mi 170Mi
kube-dns-6987857fdb-w8bd4 100m <none> 70Mi 170Mi
kube-dns-autoscaler-bb58c6784-rsklz 20m <none> 10Mi <none>
kube-proxy-gke-mw-prod-np-1-2cfd6748-k8kg 100m <none> <none> <none>
kube-proxy-gke-mw-prod-np-1-68476602-7zlg 100m <none> <none> <none>
l7-default-backend-fd59995cd-vcmd4 10m 10m 20Mi 20Mi
metrics-server-v0.3.1-57c75779f-zmbt6 43m 43m 55Mi 55Mi
prometheus-to-sd-rgdvx 1m 3m 20Mi 20Mi
prometheus-to-sd-smrbm 1m 3m 20Mi 20Mi
stackdriver-metadata-agent-cluster-level-55dfd764dd-8q674 40m <none> 50Mi <none>
Useful, but not sexy. I wanted a view of the packing onto my nodes. For this I dusted down a copy of kube-ops-view, which is something I’d played around with before. My deployment of it is largely based on the sample yaml’s with a view tweaks to secure it and make the Redis pod a little happier. This gives something visually more appealing:
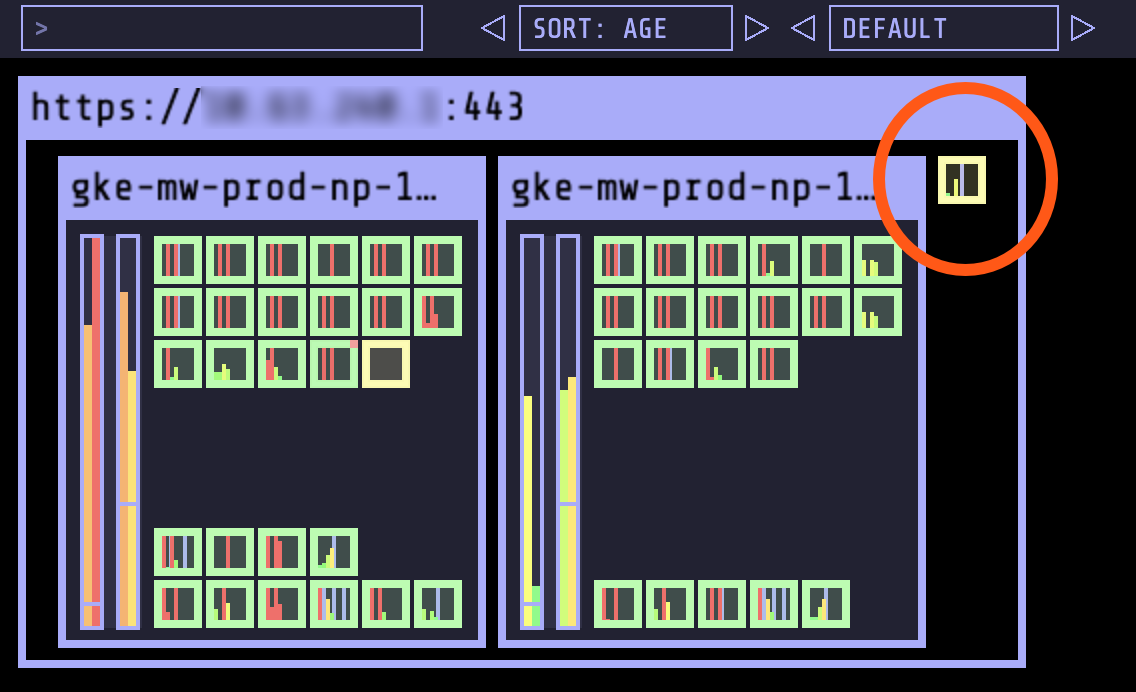
EFK won’t fit!
The red circle shows the unscheduled Elasticsearch pod. The vertical bars - in particular the amber ones, which show memory - tell us that we’re not going to be able to fit something this size on here (and Kubernetes won’t re-pack the existing workloads as it is honouring their anti-affinity rules). I actually found that even with a third node, it’d struggle because the kube-system workloads expand over time - many of them don’t have caps on resource utilisation as we see above from the sexy-bash earlier. This leaves us with pods in a Pending state and FailedScheduling errors due to Insufficient memory.
Someone Else Has Solved This, Right?

As is standard in our lovely industry, the first thing I did was of course to Google it. Someone else must’ve had this problem before, right? Turns out, Google themselves - or rather, they’ve been asked the question before and produced a handy document as a starting point.
This sounded perfect! I wouldn’t have been writing a blog post if that were true however 😞
There is some good advice in here - but a lot of it didn’t really apply for me. I wanted to keep Stackdriver Logging/Monitoring switched on in the meantime while I was experimenting - and might need the metric exports anyway later. The Kubernetes Dashboard was already switched off due to security privileges.
One thing from this documentation that I did leap on was the ScalingPolicy for fluentd - I followed this recommendation with a policy as follows and it worked a treat:
---
apiVersion: scalingpolicy.kope.io/v1alpha1
kind: ScalingPolicy
metadata:
name: fluentd-gcp-scaling-policy
namespace: kube-system
spec:
containers:
- name: fluentd-gcp
resources:
requests:
- resource: cpu
base: 10m
- resource: memory
base: 100Mi
limits:
- resource: cpu
base: 100m
- resource: memory
base: 250Mi
I was really impressed with this - and thought I’ll just do the same thing for other stuff, like kube-dns, kube-proxy, etc.
Job done right? NOPE! 👎 Turns out that, by looking a little closer, this relies on an additional component running inside GKE - fluentd-gcp-scaler - which is based on this. I fiddled a little bit with this to see if I could get the same thing running for other stuff in the cluster, before switching my focus …
Enter Vertical Pod Autoscaling
VPA is a feature that Google recently (ish) announced in Beta. It is talked about in the context of GKE Advanced / Anthos, so I may need to keep an eye on whether it becomes a chargeable product 💰 - but in the meantime, it seemed worth experimenting with.
The google_container_cluster Terraform resource already contains the option to enable GKE’s VPA addon, so turning this on was a breeze:
resource "google_container_cluster" "cluster" {
# enabling VPA needs Beta
provider = "google-beta"
# [... other important stuff ...]
vertical_pod_autoscaling {
enabled = true
}
}
As part of this I also flipped on Cluster Autoscaling just to see if the behaviours involved here caused my cluster to flex in size (I’d removed my EFK deployment at this point, so we were back at square one).
Getting VPA to do its thing involves applying some straight-forward policy, which looks a bit like this:
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: kube-dns-vpa
namespace: kube-system
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: kube-dns
updatePolicy:
updateMode: "Off"
With this yaml, we create a VPA policy in Recommendation mode - describing the VPA then tells us what it thinks the resource bounds should be. Google’s docs are reasonably cagey on how exactly it works things out, but it doesn’t seem to take too long to start making recommendations for you.
[~ (⎈ |mw-prod:kube-system)]$ kubectl describe vpa metrics-server-v0.3.1
Name: metrics-server-v0.3.1
Namespace: kube-system
# [snip]
Status:
Recommendation:
Container Recommendations:
Container Name: metrics-server
Lower Bound:
Cpu: 12m
Memory: 131072k
Target:
Cpu: 12m
Memory: 131072k
Uncapped Target:
Cpu: 12m
Memory: 131072k
Upper Bound:
Cpu: 12m
Memory: 131072k
That’s all well and good, but more fun is changing this to updateMode: "auto" and letting it actually perform the resizing these pods for you. A handy extension to your VPA definitions that can be made here is to set your own upper/lower bounds - particularly useful for situations where workloads can be spiky or extra resource is needed for pod initialisation. For example:
spec:
resourcePolicy:
containerPolicies:
- containerName: '*'
maxAllowed:
memory: 2Gi
minAllowed:
memory: 100Mi
I set some VPA definitions up for all the things in kube-system and left it for a short while to do its thing. I ended up with the following:
Original:
NAME CPU_REQ CPU_LIMIT MEMORY_REQ MEMORY_LIMIT
event-exporter-v0.2.5-7d99d74cf8-6blm5 <none> <none> <none> <none>
fluentd-gcp-v3.1.1-mzgdn 10m 100m 100Mi 250Mi
fluentd-gcp-v3.1.1-sjztp 10m 100m 100Mi 250Mi
fluentd-gcp-scaler-55bdf597c-xsxwr <none> <none> <none> <none>
heapster-v1.6.1-74885ff99d-wkjl9 13m 13m 120Mi 120Mi
kube-dns-6987857fdb-7jm2z 100m <none> 70Mi 170Mi
kube-dns-6987857fdb-w8bd4 100m <none> 70Mi 170Mi
metrics-server-v0.3.1-57c75779f-zmbt6 43m 43m 55Mi 55Mi
New:
NAME CPU_REQ CPU_LIMIT MEMORY_REQ MEMORY_LIMIT
event-exporter-v0.2.5-7d99d74cf8-drbv2 12m <none> 131072k <none>
fluentd-gcp-v3.1.1-27gs7 23m 230m 225384266 563460665
fluentd-gcp-v3.1.1-8bhv4 23m 230m 203699302 509248255
fluentd-gcp-v3.1.1-rmh47 23m 230m 203699302 509248255
fluentd-gcp-scaler-55bdf597c-dzxf5 63m <none> 262144k <none>
heapster-v1.6.1-74885ff99d-8gksk 11m 11m 87381333 87381333
kube-dns-6987857fdb-7jh59 11m <none> 100Mi 254654171428m
kube-dns-6987857fdb-dqtft 11m <none> 100Mi 254654171428m
metrics-server-v0.3.1-57c75779f-mpdvq 12m 12m 131072k 131072k
All kinds of wacky units involved! As well as occasionally recommending things at a larger size than I hoped, I also couldn’t get it to target certain resources - namely the kube-proxy pods which aren’t DaemonSets as expected (or Deployments/StatefulSets), but individual pods in the world of GKE (weird, right?). VPA unfortunately only works based on a targetRef field (rather than something like a label selector, which it looks like it used to support but now no longer does).
AutoScale ALL THE THINGS … Oops!

This seemed effective enough that I fancied rolling it out to my actual workloads too (rather than just the stuff in kube-system) - with that in mind I created a lightweight controller (inspired by some of the work my colleagues have done) - code for it is here: https://github.com/alexdmoss/right-sizer. This will skim through Deployments every 10 mins and create VPA Policies for any new workloads it spots. This had rather comedic effects with updateMode: Auto 😄, as can be seen by this screenshot from kube-ops-view:
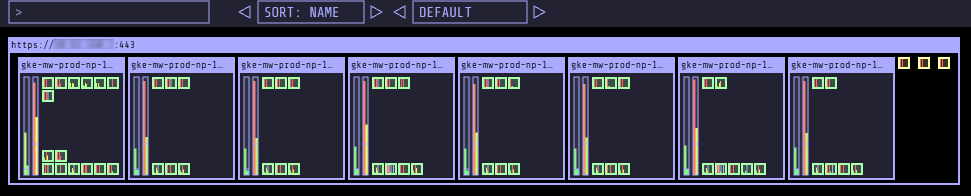
Uh-oh - bigger cluster!
This happened a few minutes after the VPA policies were created and isn’t super-surprising when you think about it. All those tiny pods of mostly nginx were getting set with a memory request of 200-500Mi, creating memory pressure on the nodes as can be seen by the red bars. For nodes with only 1Gb of spare RAM available, there was no choice but for the Cluster Autoscaler to kick in! It’s a little surprising to me that the VPA was looking at their utilisation and thinking they needed that much memory, but without knowing more about how it makes its calculations it’s hard to reason about why.
I did this as a bit of an experiment - but it’s obvious that we need to be careful with this stuff. The VPA only has limited info to go on, and unless you set resourcePolicies to cap it to sensible values (not so practical for a Controller that applies to all Deployments!) it can do some wacky things.

For obvious reasons, I switched things back to recommend-only mode for all my workloads, and then used this data to set sensible defaults that I was happy with for my pods. I then turned to a slightly more dodgy solution instead …
Right-sizing kube-system
I still had a problem. I had some recommendations from VPA, but the beefier workloads on my tiny cluster were mostly the ones residing in kube-system, for which I don’t control the Deployments.
It’s here that things get hacky. I extended my Controller (used earlier to create the VPA policies) to also set some resource requests/limits on the kube-system resources that were on the larger side. The code for it could do with some work, but it has been ticking away for a few weeks now and seems to be working out ok 😄
It works by periodically (every 10 mins) patching the pods in kube-system with new entries for memory and CPU utilisation. I opted to do this for the following:
-> [INFO] [2019-09-29 07:08] Patching kube-dns:kubedns with lower resource requests/limits
-> [INFO] [2019-09-29 07:08] Patching kube-dns:dnsmasq with lower resource requests/limits
-> [INFO] [2019-09-29 07:08] Patching heapster with lower resource requests/limits
-> [INFO] [2019-09-29 07:08] Patching heapster-nanny with lower resource requests/limits
-> [INFO] [2019-09-29 07:08] Patching metrics-server with lower resource requests/limits
-> [INFO] [2019-09-29 07:08] Patching metrics-server-nanny with lower resource requests/limits
Fluentd could be skipped because I still had the ScalingPolicy from earlier, but that would also be a good candidate.
Fundamentally, the code works like this - not too complicated:
patch = {
"spec": {
"template": {
"spec": {
"containers": [
{
"name": "kubedns",
"resources": {
"requests": {
"cpu": "10m",
"memory": "50Mi",
},
"limits": {
"cpu": "100m",
"memory": "100Mi",
}
}
}
]
}
}
}
}
def patch_deployment(name: str, patch: str):
api_instance = client.AppsV1Api()
try:
api_instance.patch_namespaced_deployment(
name=name,
namespace='kube-system',
force=True,
field_manager='right-sizer',
body=patch)
except client.rest.ApiException as e:
logger.error(f"Failed to patch deployment: {name} - error was {e}")

As a general approach, I’m not sure how I’d feel about doing this sort of thing in Production for an important system. Google will no doubt be reconciling these things themselves - we’re effectively overwriting their chosen settings on a more frequent basis - hence my “hacky” comment. But, for a small cluster used for less important things, this approach does seem to have worked out okay.
Conclusions

So, can I run Elastic now? Yes!
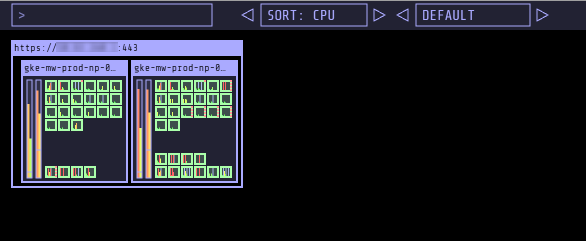
Final Squeeze - Everything Runs
As can be seen above, we’ve just about got it squeezed onto a pair of n1-standard-1’s (so slightly bigger machines than when we started, but only two of them - so cost neutral, more or less).
More useful for me really is that I learnt some interesting things about VPA and right-sizing of workloads, and some idiosyncrasies in how GKE manages pods in the kube-system namespace.
Evolution?
I was sufficiently impressed with VPA in an advisory capacity that it seemed worth a closer look in a work context too. At a larger scale the savings in Compute could become quite significant - depending on the maturity of testing practices in your teams (some of our teams at work are very good at right-sizing their workloads already, whereas some could probably use the help).
We’ve therefore recently enabled it in Recommendation mode and started bringing the results into Prometheus and visualising them against current utilisation through Grafana - early days, but it looks really cool and I’d like to replicate the same in my home setup. Some of the recommendations are pretty quirky though, so it may need a bit more time to bed in … and letting it auto-resize is unlikely to be viable for us given the amount of JVM-based workloads we run (it can’t also set -Xmx, for example).
In Summary
- Get a tool that helps you visualise your resource requests/limits/utilisation. I like kube-ops-view as it’s simple but effective
- Google have an article with specific advice for GKE. Many of the recommendations won’t be suitable, but things like disabling the Kubernetes Dashboard and taking advantage of their fluentd autoscaler are good quick wins
- In GKE, enable the VerticalPodAutoscaler addon and apply some VPA policies targeting the deployments you are interested in. I started in “Recommend” mode to see what it was going to do first
- If you’d like a custom controller to setup VPA for all your deployments, have a nose at this for inspiration
- If you’re comfortable with the recommendations and that your workloads can tolerate the restarts - switch on update mode and forget about needing to right-size your workloads (… in theory)
- To really squeeze things down, you can update
kube-systemresources with a custom controller which does the equivalent ofkubectl patchon the resource requests/limits on a regular basis